この記事のきっかけ
仕事中、Next.jsで描画する画面で「ある文字列の20文字目までは表示したい、21文字目以降は '...' で省略したい」という仕様がありました。 こういう要件は度々あって、すでにプロジェクト内には String.prototype.substring()を利用したそれ用の関数が用意されています。しかし、String.prototype.substring()ってどんな文字で期待通りに動くのかなとふと疑問になって調べていくうちに、やはりうまく動かない場合があること、Intl.Segmenterがに合わせた処理ができることを知ったので書き留めておきます。
String.prototype.substring()
String.prototype.substring()の詳しいことはMDNに任せるとして、例えばこんなふうに使うことができます。
const str = "こんにちは" // UTF-16のcode unit単位で、strの0番目から1番目までを表示する console.log(str.substring(0, 1)) // => 'こ'
String.prototype.substring() で困ったこと
基準がUTF-16のcode unitなので、1文字で2ユニット分ある文字だと人間の直感的な期待値と戻り値が変わってきます。以下のように、ベースとなる文字とは異なる文字が戻り値に含まれていたり、文字化けのようになったりします。
const str = "𩸽は美味しい" console.log(str.substring(0, 1)) // => � console.log(str.substring(0, 2)) // => 𩸽
絵文字でも同じことが起こります。(絵文字がコードブロック等では文字化けしてしまうのでスクショ貼っておきます)

Intl.Segmenterを利用する
この問題を解決するにはIntl.Segmenterがあるようです。
MDNでのIntl.Segmenter() constructorの説明に
The Intl.Segmenter object enables locale-sensitive text segmentation, enabling you to get meaningful items (graphemes, words or sentences) from a string.
とあるように、オプションでロケールを渡すことができて、そのロケールに合わせて文字列をセグメントに分割したオブジェクトを生成してくれるのがIntl.Segmenterです。
インスタンスメソッドIntl.Segmenter.prototype.segment()に処理したい文字列を渡すと、分割した結果を得ることができます。
const str = "𩸽は美味しい" const segmenter = new Intl.Segmenter('Ja-jp', { granularity: 'grapheme' }); // 人間から見た1文字ずつで処理 console.table(Array.from(segmenter.segment(str)))
出力は次のようになります。
| (index ) | segment | index | input |
|---|---|---|---|
| 0 | 𩸽 | 0 | 𩸽は美味しい |
| 1 | は | 2 | 𩸽は美味しい |
| 2 | 美 | 3 | 𩸽は美味しい |
| 3 | 味 | 4 | 𩸽は美味しい |
| 4 | し | 5 | 𩸽は美味しい |
| 5 | い | 6 | 𩸽は美味しい |
このテーブルの(index)がArrayとしての順番で、Intl.Segmenterが持っている方のindexはコードユニットでカウントした時に何番目かという値になっているため、「人間が見たときの2文字目」を取得したい場合はArray.from(segmenter.segment(str))[1]で取得できました!
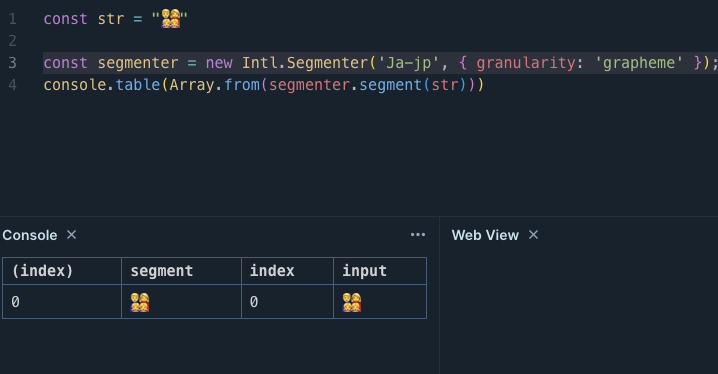
また絵文字も問題なく動きそうです。(👨👩👧👧がコードブロック等では文字化けしてしまうのでスクショ貼っておきます)
その他
本題から逸れるのでこのエントリからは書いてないんですが、MDNのIntlのページを読んでいると、色々な工夫や「そんなふうに使うといいのか」というものがあって読んでいて楽しいです。(別件で、西暦を和暦に変換したい時にもIntlにお世話になりました)